Les cours suivis d’un astérisque seront dispensés en anglais.
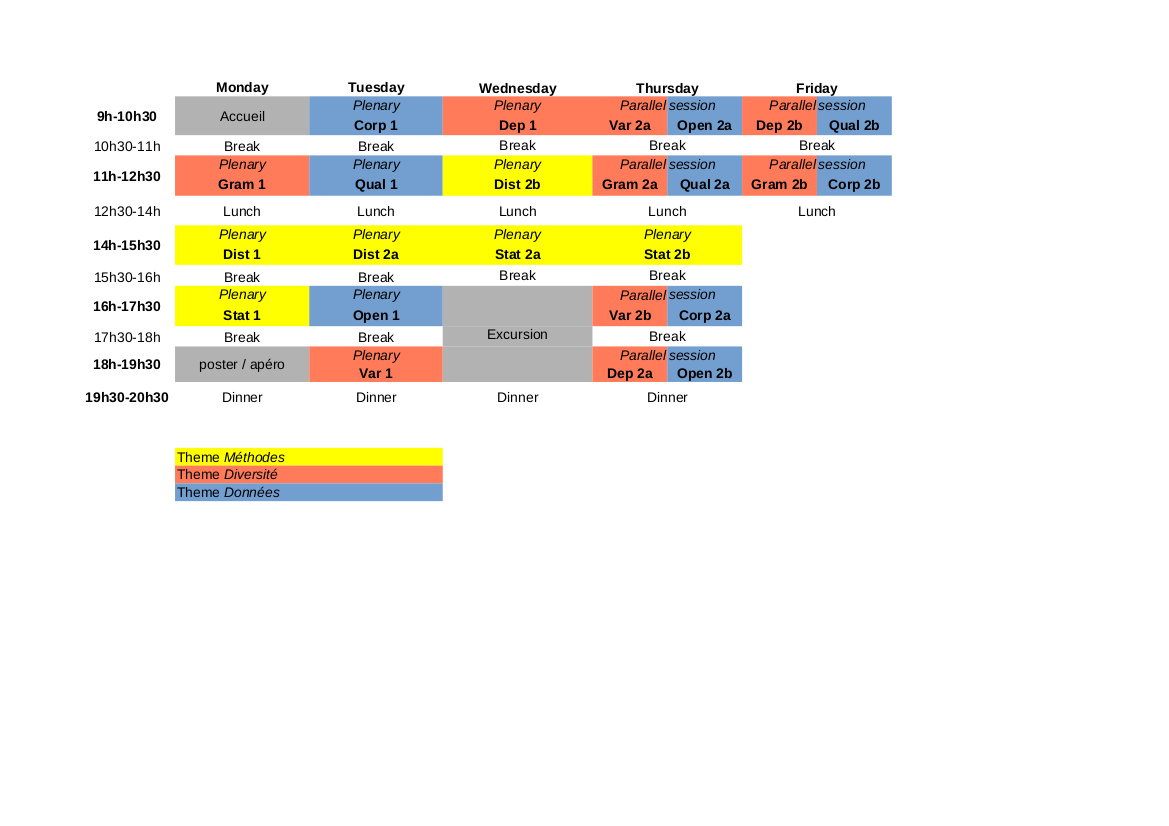
Cours et enseignants
1/ Méthodes statistiques et géométriques de représentation en syntaxe et sémantique
- Benoît Crabbé (LLF, U Paris) et Guillaume Wisniewski (LLF, U Paris) : Statistique et apprentissage automatique (Stat)
- Gemma Boleda (U Pompeu Fabra, Barcelona) : Distributional Semantics (Dist)
2/ Modélisation de la diversité des langues : approche formelle et approche empirique
- Emily Bender (U Washington) : Typologie computationnelle, implémentation de grammaires* (Gram)
- Kim Gerdes (LISN, U Paris-Saclay) : Universal Dependencies (Dep)
- Sylvain Loiseau (Lacito, U Paris 13) : Variation trans-linguistique (Var)
3/ Corpus et données : partage, qualité, reproductibilité et science ouverte.
- Karën Fort (Sorbonne Université / LORIA) : Qualité des annotations (Qual)
- Alexis Michaud (Lacito, CNRS) : Corpus partageables (Corp)
- Timo Roettger (Universitetet i Oslo) : Open Science* (Open)
4/ Table ronde (Animation : Claire Gardent) ; Présentations de projets
Distributional Semantics
(U Pompeu Fabra, Barcelona)
This course covers the basics of distributional semantics, an approach to meaning that is very prominent in computational linguistic and cognitive science. Distributional semantics provides multi-dimensional, graded, empirically induced representations that successfully capture many aspects of meaning in natural languages. The course provides an overview of the approach and a critical discussion of the methods and results in distributional semantics that are of relevance for theoretical linguistics. It covers three areas: semantic change, polysemy and composition, and the grammar-semantics interface (specifically, the interface of semantics with syntax and with derivational morphology). We will finish with a brief look at more complex models that are nowadays state of the art in computational linguistics.
The course features theoretical parts (lectures) and practical parts where students will be able to use distributional models. No previous programming experience is required. Please bring a laptop if you can.
Day 1: Introduction.
Day 2: Polysemy and composition. Semantic change.
Day 3: Grammar-semantics interface. Outlook.
Typologie computationnelle, implémentation de grammaires
(University of Washington)
Lectures will be in English, but the lecturer is happy to take questions in French.
Part 1
In this lecture, I will introduce grammar engineering (the practice of creating grammars as software) and the present the Grammar Matrix project, which can be understood as both an approach to computational linguistic typology and a toolkit for facilitating the development of precision HPSG grammars. The Grammar Matrix consists of a core grammar, shared across languages, and a customization system which provides analyses to specification for cross-linguistically variable phenomena. I will describe how Grammar Matrix developers extend and test the customization system. Finally, I will demonstrate the use of the customization system and the basic functionality of the associated grammar development environments. This initial lecture will provide students with an overview of the technology and an introduction to its user community.
Part 2a
This session will provide a deeper exploration of the AGGREGATION project, which seeks to create grammar specifications based on automatic processing of interlinear glossed text (IGT). IGT is a rich datatype commonly produced by field and descriptive linguists as they work on primary linguistic description. I will provide an overview of the AGGREGATION project and we will jointly explore the output of the system for a specific IGT dataset, at both the level of the grammar specification and at the level of the grammar. The session will also include a discussion of what makes IGT suitable for this kind of treatment.
If anyone at the summer school has IGT that AGGREGATION can work with (Toolbox format, glosses in English), I can try to see if we can use that dataset for demonstration purposes. Please contact me as soon as possible to discuss.
Part 2b
This session will provide a deeper exploration of grammar development, testing, and grammar-based treebanking. I will demonstrate how to refine/extend a customized grammar (i.e. the output of the customization system) through hand-editing of the grammar source code, how to evaluate changes to a grammar with regression testing, and finally how to use a grammar for creating a treebank. The discussion of treebanking will include considerations of integrating treebanks into descriptive grammatical resources as well as other practical applications of treebanks.
Recommended software for this course is the Ubuntu+LKB virtual box appliance.
Unfortunately, this does not work with Mac computers with the M1 chip. The software is not required, only provided so that students who wish to can follow along on their own computers.
Statistics and machine learning
(LLF, U Paris)
The aim of this course is to introduce the main concepts of statistics and to explain why and how they can be used to conduct research in linguistics.
Lecture n°1: descriptive statistics
We will introduce the different kind of variables that can be used to describe observations in linguistics, the main quantities that can be used to summarize them (mean, variance, median, ...) and how they can be represented graphically.
Lecture n°2 & 3: inferential statistics
We discuss how we can expect to generalize observations from a finite set examples to a full population in order to draw “generic conclusions” from them.
Qualité des annotations
(Sorbonne Université / LORIA)
In the past 20 yeast, the overwhelming influence of machine learning in NLP has (for better or for worse) largely shifted the linguistic formalization from local grammars to manual annotation, at least for the systems' evaluation. However, the manual annotation process remains ill-defined and ill-managed. This course will present the issues at stake related to manual corpus annotation formalization and evaluation.
In the first class (Qual1), I'll introduce what collaborative annotation is and why we need guidelines, with a simple annotation exercice. I'll then present the complexity grid (Fort et al., 2012), which allows to identify the specifics of the annotation task at hand, in order to apply the appropriate tools and methods.
During the parallel sessions, I'll deal with:
- Qual2a -- Inter-annotator agreement: I'll present the principles behind inter-annotator agreement computation and some of the most well-known metrics (Pi, Kappa) (Artstein and Poesio, 2008, Mathet and Widlöcher, 2015). I'll show their application scope and limits in terms of semantic interpretation (Mathet et al. 2012). An exercice will be proposed to apply some of the metrics. This course is based on a presentation prepared in collaboration with Yann Mathet.
- Qual2b -- Crowdsourcing: this class will be devoted to crowdsourcing, especially using games with a purpose and citizen science platforms (Fort, 2016). I'll propose you to design a game with a purpose, which might be developed in the framework of the CODEINE ANR project.
- The content of the course will be largely based on the one I teach at Sorbonne Université (Master 2 : "Annotation collaborative de corpus", in French)
Main references:
- Artstein, R. & Poesio, M. Inter-Coder Agreement for Computational Linguistics Computational Linguistics, MIT Press, 2008, 34, 555-596. http://www.mitpressjournals.org/doi/abs/10.1162/coli.07-034-R2
- Karën Fort. Collaborative Annotation for Reliable Natural Language Processing: Technical and Sociological Aspects. Wiley-ISTE, pp.196, 2016, 978-1-84821-904-5. https://hal.archives-ouvertes.fr/hal-01324322/file/CollaborativeAnnotation_ExemplaireAuteurNonCorrig%C3%A9.pdf
- Karën Fort, Adeline Nazarenko, Sophie Rosset. Modeling the Complexity of Manual Annotation Tasks: a Grid of Analysis. International Conference on Computational Linguistics, Dec 2012, Mumbaï, India. pp.895–910. https://hal.archives-ouvertes.fr/hal-00769631/file/coling2012_Complexity_KF_30102012.pdf
- Bruno Guillaume, Karën Fort, Nicolas Lefèbvre. Crowdsourcing Complex Language Resources: Playing to Annotate Dependency Syntax. International Conference on Computational Linguistics (COLING), Dec 2016, Osaka, Japan. https://hal.inria.fr/hal-01378980/file/coling2016_zl.pdf
- Yann Mathet, Antoine Widlöcher, Karen Fort, Claire François, Olivier Galibert, Cyril Grouin, Juliette Kahn, Sophie Rosset, Pierre Zweigenbaum. Manual Corpus Annotation: Giving Meaning to the Evaluation Metrics. International Conference on Computational Linguistics, Dec 2012, Mumbaï, India. pp.809–818. https://hal.archives-ouvertes.fr/hal-00769639/file/coling2012_EvalManualAnnotation.pdf
- Mathet, Y.; Widlöcher, A. & Métivier, J.-P. The Unified and Holistic Method Gamma (γ) for Inter-Annotator Agreement Measure and Alignment Computational Linguistics, 2015, 41, 437-479. http://www.mitpressjournals.org/doi/pdf/10.1162/COLI_a_00227
Universal Dependencies
(LISN, U Paris-Saclay)
Session 1
- Short history, aims, scope, and recent developments of the Universal Dependencies Project
- Building a new treebank from scratch: annotation tools, bootstrapping, collaborative annotation, annotation guidelines, Grew rewriting grammars, error mining
Session 2a
Typometrics:
- Treebank exploration using Grew
- Global statistics on UD
- Quantitative Universals in Word Order Typology
Session 2b
- Hands-on treebank development
- Using Arborator
- Configuration, annotation, bootstrapping
Typological diversity in linguistic research
(Lacito, U Paris 13)
This course will illustrate the field of linguistic diversity for researchers with primarily formal or computational background. It will illustrate the linguistic diversity in linguistic structures, and the challenge it poses to the notion of unrestricted universal, as well as the difficulty of comparing languages and extracting generalizations from all the observed diversity.
The first slot will focus on the notion of linguistic diversity. It will discuss the bias towards "standard European languages" in linguistic research, the increasingly complex picture of variation in human languages that is emerging from current efforts in descriptive linguistics and how this challenges the idea of unrestricted universals. We will emphasize the importance of considering data representing actual diversity, issues of comparability/commensurability across languages as well as sampling issues.
The second slot will be devoted to methods and concepts in linguistic typology, and how this field results in a particular framework of description of its own. We will discuss some typological frameworks and notions, such as the canonical typology framework, implicational universals, hierarchies, and the explanation of typological regularities. Examples will be drawn in particular from the field of lexical typology.
The third slot will present the Papuan language area. Its internal diversity as well as some of its recurrent properties will be highlighted, such as clause chaining (typical of right-headed languages), switch reference systems, co-coordination constructions, complex gender systems.
Corpus partageables
(Lacito, CNRS)
Designing data collection so as to facilitate data curation and data re-use The second half of the 20th century was the dawn of information technology; and we now live in the digital age. The ease with which anyone can now do recordings should not veil the complexity of the data collection process, however. The talk aims at sensitizing students and scientists from the various fields of speech and language research to the fact that speech-data acquisition is an underestimated challenge. Eliciting data that reflect the communicative processes at play in language requires special precautions in devising experimental procedures. Extra effort put into reflecting on the elicitation process (including from the speaker's perspective) and on the technical choices pays off in terms of facilitating curation and data re-use. The course recapitulates basic information on each of these requirements and some pieces of practical advice, drawing many examples from prosody studies, a field where the thoughtful conception of experimental protocols is especially crucial.
Two references:
- "Speech data acquisition: the underestimated challenge" https://halshs.archives-ouvertes.fr/halshs-01026295
- "Toward open data policies in phonetics: What we can gain and how we can avoid pitfalls" https://halshs.archives-ouvertes.fr/halshs-02894375/
Open Science*
(Universitetet i Oslo)
Plenary: The Credibility Revolution - Reasons for and solutions to the replication crisis.
Option 1: Preregistration - What is it and how does it work?
Option 2: How to be transparent? Reproducible workflows for linguists.
Our understanding of language, cognition and society is increasingly shaped by quantitative research. With a rapidly growing body of quantitative evidence, it is of critical importance to both being able to evaluate existing findings in the literature and ensuring the rigour of the research we are producing right now. In order to achieve these goals, quantitative fields made a turn toward open and reproducible practices. The course discusses this ongoing movement, reflects on its implications for linguistic research and introduces tools to achieve transparency, reproducibility and rigour across the language sciences. Concretely, the course introduces reproducible workflows, including their implementation into existing processes. We will introduce practical solutions and tools that help linguistic researchers overcome barriers to reproducibility and practice using these tools in hands-on activities.